Aperçu du projet
Pour ENPH 353, mon partenaire George et moi avons construit “HTTP 418” — un système de contrôle pour un robot autonome de recherche d’indices opérant dans une simulation Gazebo. L’objectif du robot était de naviguer sur un parcours tout en lisant des indices sur des panneaux, en évitant les piétons et les véhicules, le tout en utilisant uniquement sa caméra embarquée. Le projet a culminé avec une compétition où les robots s’affrontaient pour collecter tous les indices correctement.
Rapport complet PDF | Dépôt GitHub
Architecture du système
Le système de contrôle est construit comme une collection de nœuds ROS connectés par des topics et services. Cette architecture découplée nous a permis de tester les composants individuellement et de gérer des contraintes de calcul variées — le modèle de direction fonctionne à la fréquence de la caméra tandis que le modèle YOLO OCR tourne sur des GPU cloud.

Les composants principaux :
- inference_node : Pilote le robot en utilisant un modèle ONNX entraîné par apprentissage par imitation
- clue_detector_node : Trouve les panneaux bleus via filtrage HSV et envoie les découpes à un service YOLO hébergé sur Modal
- pedestrian_tracker_node : Utilise YOLO12n pour la détection des piétons et véhicules
- clue_collector_node : Agrège les résultats OCR par vote par histogramme
- crash_detector_node : Surveille les états bloqués et téléporte le robot pour récupérer
Reconnaissance de panneaux avec YOLO
Plutôt que d’entraîner un CNN traditionnel pour l’OCR, nous avons réutilisé YOLO pour détecter des caractères individuels. L’idée était d’obtenir un seul modèle pour tout gérer : panneaux, lettres, piétons et véhicules.
Entraînement cloud
L’entraînement de YOLO localement était péniblement lent. Nous avons loué une instance Runpod avec quatre RTX 5090, ce qui nous a permis d’itérer sur les modèles en heures au lieu de jours. Avec environ 100 Go de données d’entraînement synthétiques, nous pouvions entraîner un grand modèle YOLO jusqu’à quasi-convergence en une nuit.

Détection classique de panneaux
YOLO avait du mal à détecter les bordures bleues des panneaux de manière fiable, même s’il excellait dans la reconnaissance de caractères. Nous sommes revenus au seuillage HSV pour trouver les panneaux — la bordure bleue a une couleur unique qui n’apparaît nulle part ailleurs sur la carte.

Une fois un panneau trouvé, nous le découpions et envoyions uniquement cette région à YOLO pour l’OCR. Cette approche hybride fonctionnait bien mieux que la détection YOLO de bout en bout.
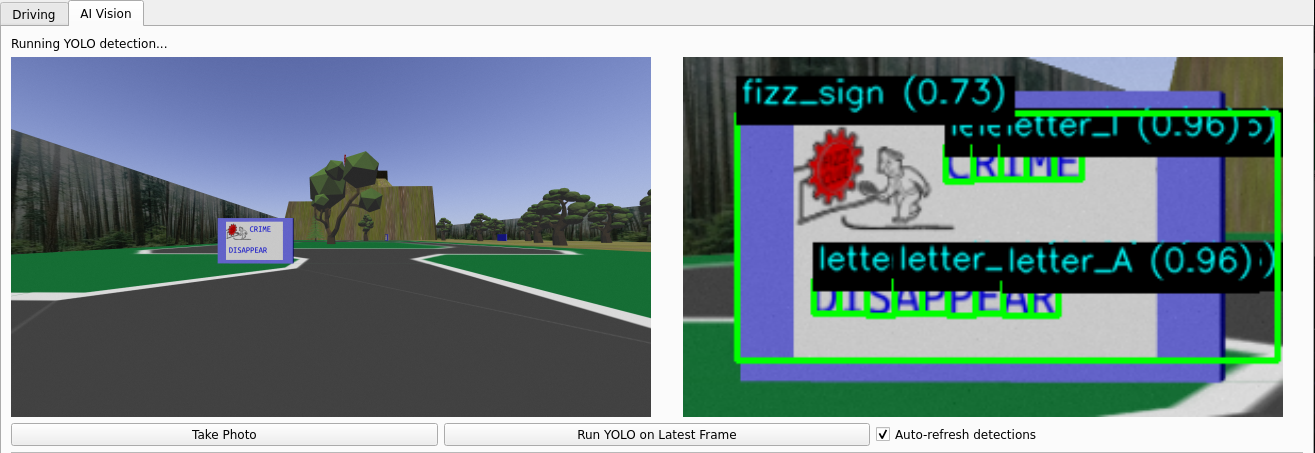
Endpoint Modal pour l’inférence
Comme l’OCR pouvait être découplé de la simulation, nous avons déployé notre modèle YOLO sur les GPU serverless de Modal. Le robot diffusait les images sur le réseau, et Modal s’auto-adaptait pour les traiter. Cela nous permettait d’obtenir 20-30 prédictions OCR par panneau, même en conduisant vite.
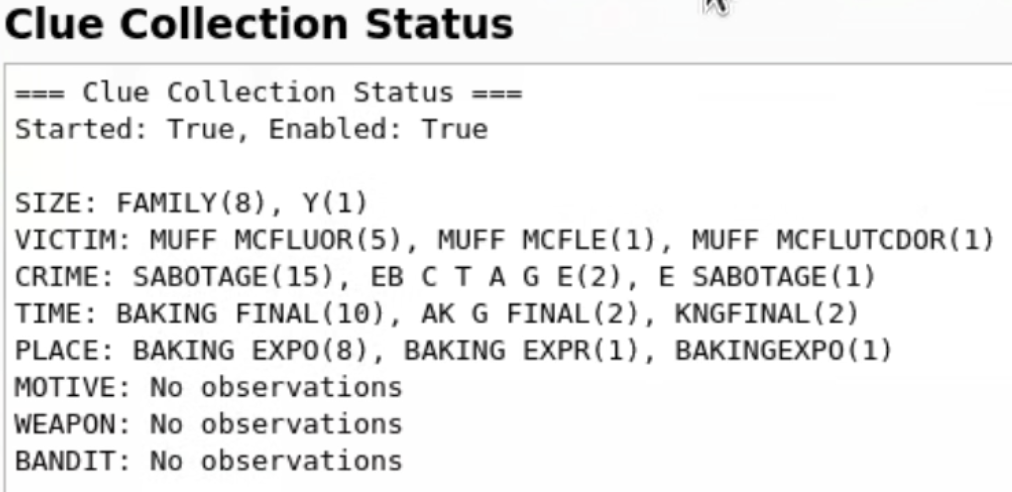
Vote par histogramme
Avec de nombreuses prédictions par panneau, nous avions besoin d’un moyen de choisir la bonne. Le clue_collector_node maintient un histogramme pour chaque type d’indice, et publie toutes les 2 secondes la valeur la plus fréquemment observée. Cette simple approche de vote majoritaire gérait bien les erreurs OCR.
Suivi de ligne : RL vs IL
Tentatives d’apprentissage par renforcement
Mon premier instinct était d’utiliser l’apprentissage par renforcement. J’ai essayé DQN, Double DQN, SAC et PPO avec diverses fonctions de récompense basées sur la progression vers des points de passage.
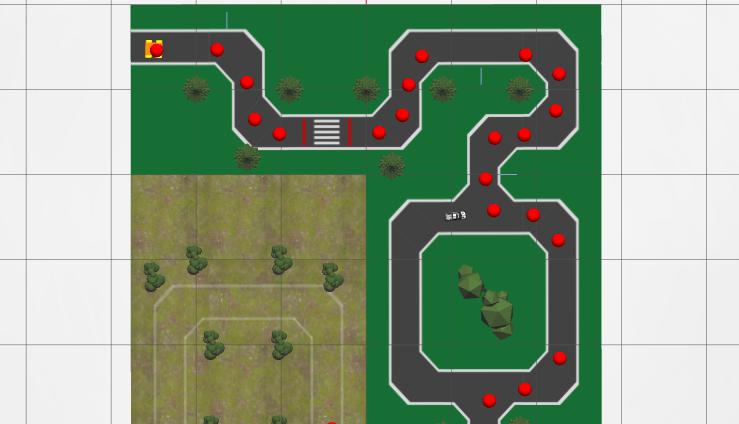
L’implémentation PPO avec RLlib a montré le plus de promesses — le modèle a appris à suivre la ligne dans des scénarios limités :
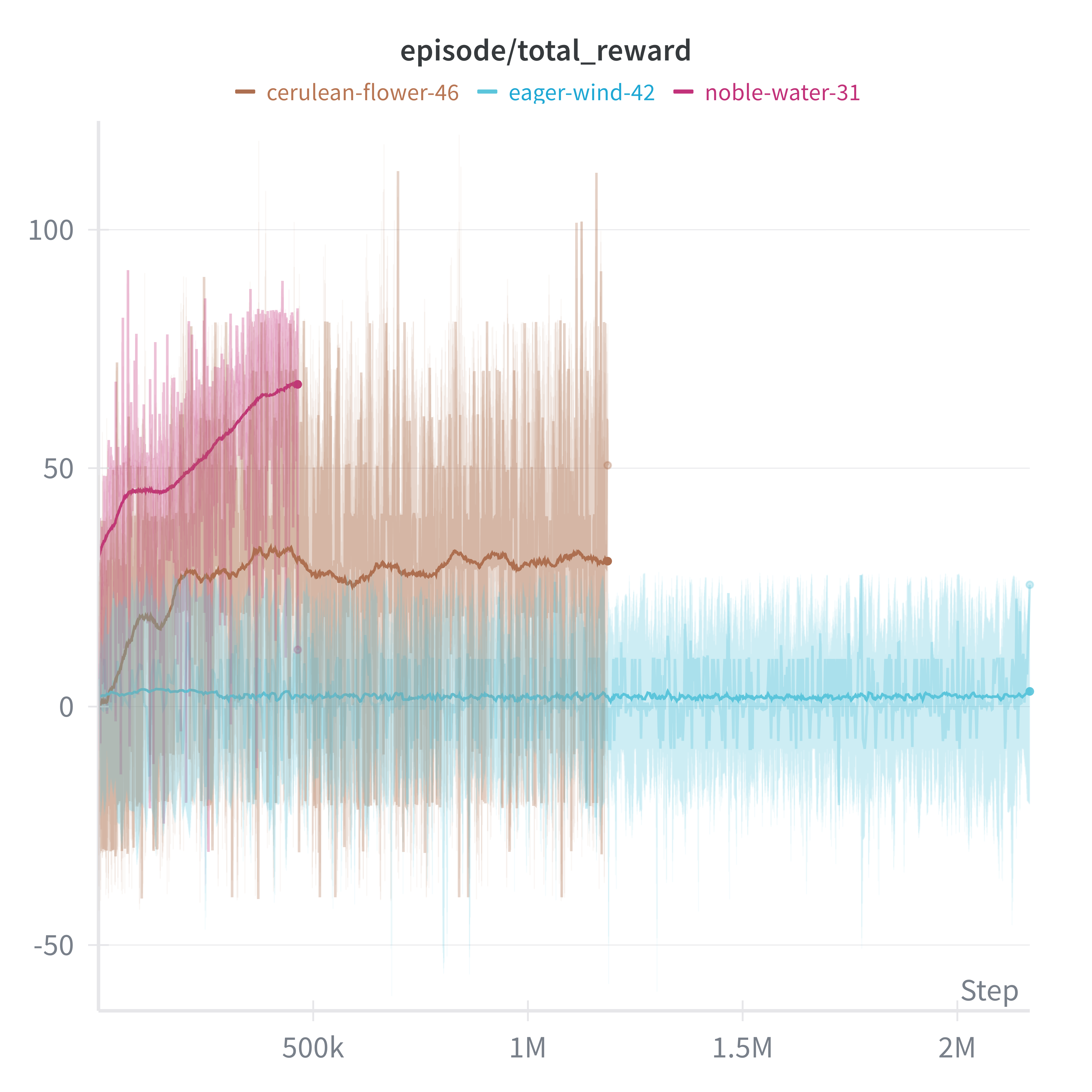
Mais les temps de convergence étaient brutaux : 48-72 heures par configuration. Avec seulement quelques jours avant la compétition, le RL n’allait pas fonctionner. Le goulot d’étranglement fondamental était le calcul — le facteur temps réel de Gazebo sur mon portable signifiait que chaque seconde d’entraînement prenait deux secondes de temps réel.
Apprentissage par imitation
Nous sommes passés à l’apprentissage par imitation, où le robot apprend en imitant des démonstrations humaines. J’ai construit une GUI de collecte de données où je pouvais conduire sur le parcours avec les flèches du clavier tout en enregistrant les images et les valeurs de direction.
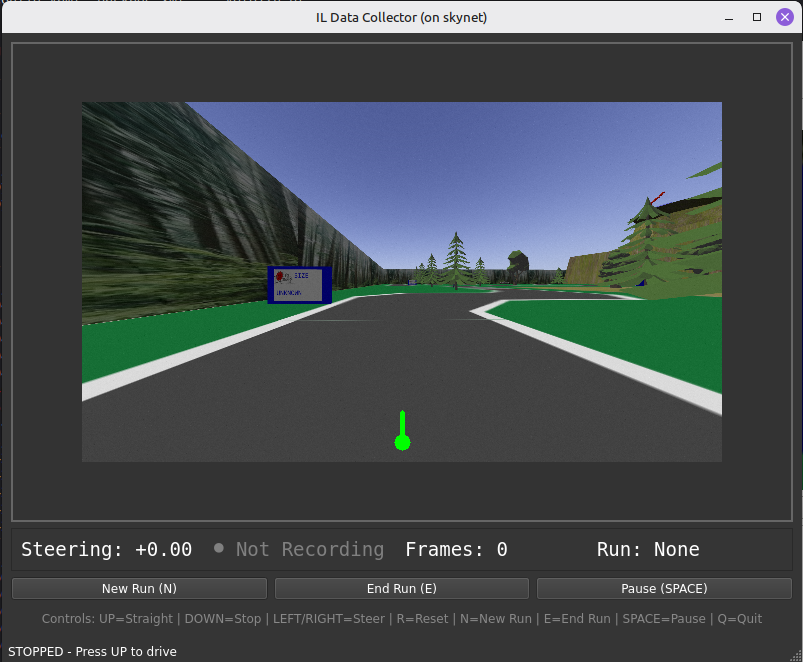
L’idée clé était d’utiliser une interpolation lisse sur les entrées clavier. Quand vous appuyez gauche/droite, la direction cible passe à -1 ou +1, mais la valeur réelle interpole en douceur. Cela donne des étiquettes continues à partir d’entrées discrètes, empêchant un comportement saccadé.
Notre architecture de modèle était basée sur l’article d’apprentissage de bout en bout de NVIDIA : des couches convolutives pour réduire les dimensions spatiales, suivies de couches denses, avec une sortie tanh pour la direction dans [-1, 1]. Après environ une heure d’entraînement sur ~30k images, le modèle pouvait suivre la ligne de manière fiable.
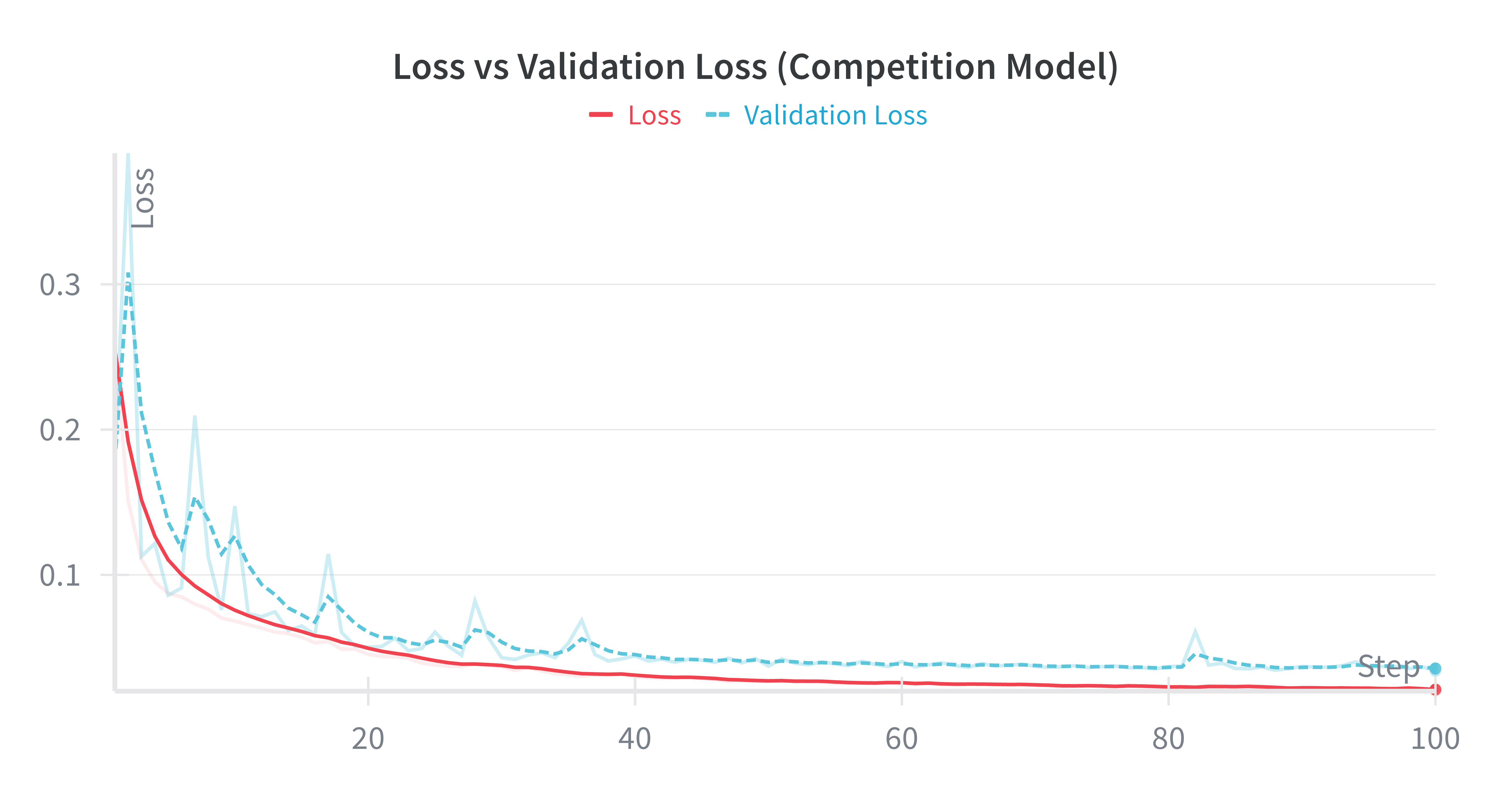
Nous avons exporté au format ONNX pour découpler l’entraînement (Python/TensorFlow moderne) du déploiement (l’ancien environnement Python de ROS).
Résultats et problèmes à la compétition
L’OCR YOLO fonctionnait bien quand ça marchait. La matrice de confusion montre de fortes performances diagonales sur les caractères :
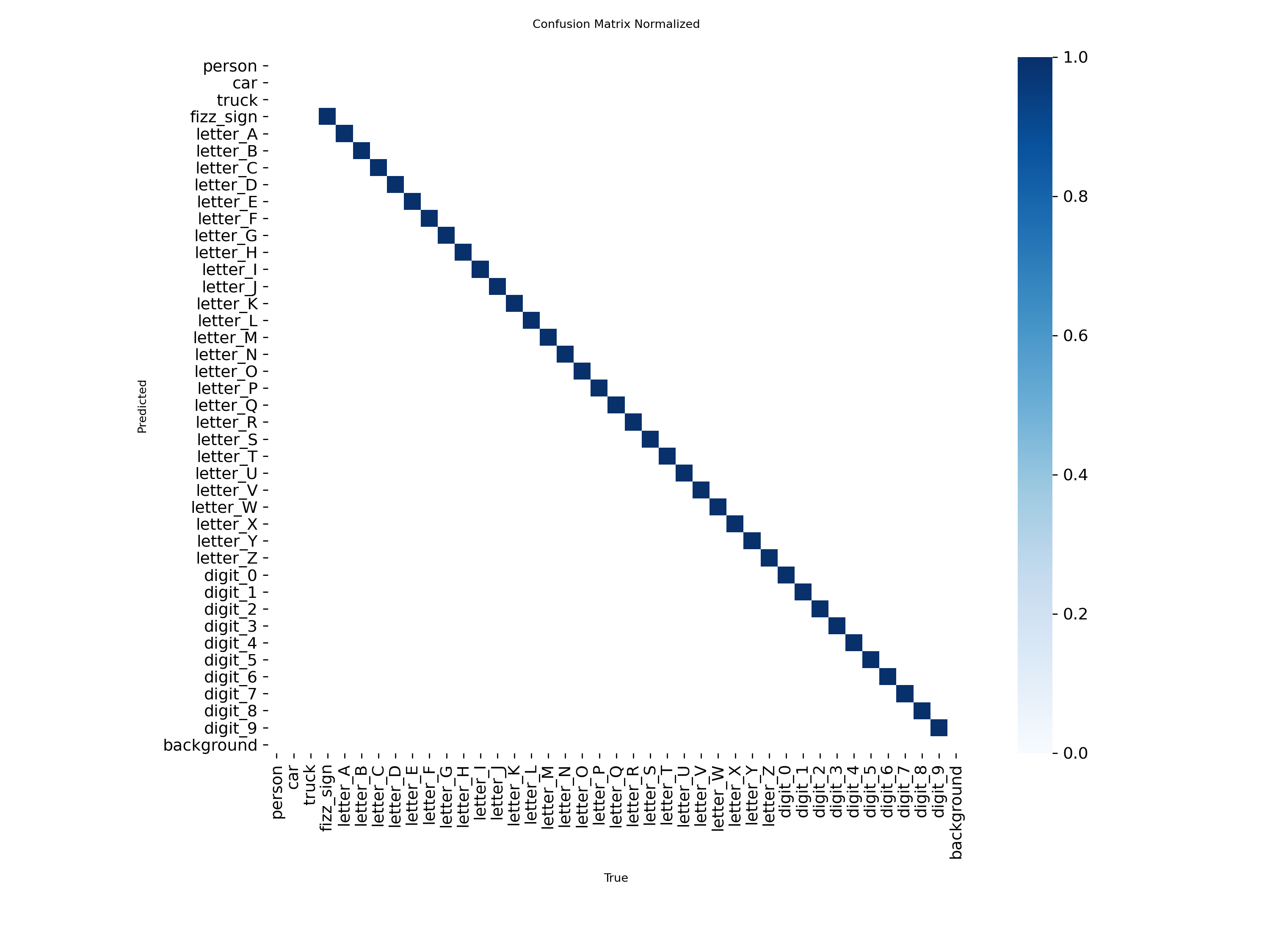
Cependant, nous avons découvert la veille de la compétition que des chiffres seraient dans la banque d’indices — et notre modèle n’était pas entraîné dessus. Nous avons hâtivement réentraîné mais avons accidentellement déployé l’ancien modèle.
Le plus gros problème était un bug de logique de réapparition. Nous avions ajouté une logique pour réapparaître au camion garé si le robot tombait dans l’eau après avoir lu les premiers panneaux. Mais cela réinitialisait l’état de détection de passage piéton, causant le robot à attendre indéfiniment dans le tunnel pour un piéton qui n’existait pas.
Leçons apprises
- IL » RL pour un temps limité : L’apprentissage par imitation convergeait en heures là où le RL prenait des jours. Pour les projets à temps limité, les démonstrations humaines sont incroyablement efficaces en données.
- Le calcul cloud est bon marché : Une machine quad-5090 coûte quelques dollars par heure. Ne souffrez pas avec un entraînement local lent.
- Les approches hybrides fonctionnent : YOLO pour les caractères + HSV pour les bordures de panneaux surpassait YOLO de bout en bout.
- Testez vos artefacts de déploiement : Nous avons déployé un modèle sans les classes dont nous avions besoin. Vérifiez toujours ce qui tourne réellement.
- Les cas limites dans les machines à états vous tuent : Le bug d’interaction réapparition-passage piéton nous a coûté la compétition.
Division du travail
Je me suis concentré sur la conduite (tentatives RL et IL), l’architecture du système, et l’approche YOLO OCR. George a géré l’entraînement du modèle de reconnaissance de caractères et la collecte/réglage des données IL. Nous avons tous deux travaillé sur la configuration réseau pour la compétition, qui impliquait du calcul cloud, des serveurs maison, des VPN Tailscale, et même des haut-parleurs Bluetooth pour notre serveur de musique de célébration.
Pour les détails techniques complets, les architectures de modèles et les résultats supplémentaires, voir le rapport complet.